Čiščenje dodatnih DUTB podatkov (odprti podatki, 2. del)
V tokratnem prispevku si bomo pogledali kako uvoziti in prečistiti podatke o podjetjih prenesenih na DUTB, ki jih je DUTB dodatno objavila na svoji spletni strani. Gre za podatke o slabih terjatvah Factor banke, Probanke in Abanke Vipa.
Kot smo že ugotovili, podatki o podjetjih objavljeni na DUTB nimajo nikakršnega uporabnega identifikatorja, ki bi omogočal enolično povezovanje z drugimi podatkovnimi bazami (npr. matične ali davčne številke). Podatke je zato potrebno povezati s PRS registrom, kar pa ni povsem enostavno, saj je DUTB objavila podjetja z imeni, ki se ne ujemajo z imeni teh podjetij v PRS registru (dodan je namreč še kraj sedeža podjetja, kakšen presledek, itd.).
Uvoz in osnovno čiščenje DUTB podatkov
Podatke torej najprej prekopiramo iz spletne strani v urejevalnik teksta, nato pa v podatkovni bazi ustvarimo tri tabele ter podatke uvozimo vanje:
create table dutb_podjetja_abanka (firma text, sedez text, izpostavljenost text); \COPY dutb_podjetja_abanka from 'Abanka_podjetja.txt' with csv header delimiter E'\t';
create table dutb_podjetja_probanka (firma text, sedez text, izpostavljenost text); \COPY dutb_podjetja_probanka from 'Probanka_podjetja.txt' with csv header delimiter E'\t';
create table dutb_podjetja_factorbanka (firma text, sedez text, izpostavljenost text); \COPY dutb_podjetja_factorbanka from 'Factor_banka_podjetja.txt' with csv header delimiter E'\t';
Opomba: pri podatkih Abanke Vipa nismo uvozili podatkov o obveznicah (vrednost obveznic je 995.458,76 EUR).
Sledi nekaj preprostih postopkov čiščenja podatkov:
update dutb_podjetja_abanka set firma = trim(firma); update dutb_podjetja_abanka set sedez = trim(sedez); update dutb_podjetja_abanka set izpostavljenost = trim(izpostavljenost);
update dutb_podjetja_probanka set firma = trim(firma); update dutb_podjetja_probanka set sedez = trim(sedez); update dutb_podjetja_probanka set izpostavljenost = trim(izpostavljenost);
update dutb_podjetja_factorbanka set firma = trim(firma); update dutb_podjetja_factorbanka set sedez = trim(sedez); update dutb_podjetja_factorbanka set izpostavljenost = trim(izpostavljenost);
Uparjanje DUTB podatkov s PRS registrom
V nadaljevanju najprej uparimo DUTB podatke s podatki iz PRS registra in sicer tako, da poiščemo vnose, kjer se ime (“firma“) podjetja iz tabele dutb_podjetje_* ujema s kratkim imenom (“kratko_ime“) iz PRS registra. Pred tem v posamezne DUTB tabele dodamo še spremenljivko davcna:
alter table dutb_podjetja_factorbanka add column davcna integer; update dutb_podjetja_factorbanka set davcna = prs_enota_rs.davcna from prs_enota_rs where (firma = trim(kratko_ime)) and (prs_enota_rs.maticna like '%000');
alter table dutb_podjetja_abanka add column davcna integer; update dutb_podjetja_abanka set davcna = prs_enota_rs.davcna from prs_enota_rs where (firma = trim(kratko_ime)) and (prs_enota_rs.maticna like '%000');
alter table dutb_podjetja_probanka add column davcna integer; update dutb_podjetja_probanka set davcna = prs_enota_rs.davcna from prs_enota_rs where (firma = trim(kratko_ime)) and (prs_enota_rs.maticna like '%000');
Po uparjanju na opisan način se izkaže, daje bilo uparjanje delno uspešno pri podatkih o podjetjih iz Factor banke in Probanke, pri Abanki pa do ujemanja ni prišlo v nobenem primeru. Zato bomo v nadaljevanju uporabili iskanje oz. uparjanje po podobnosti (ang. similarity search).
Najprej namestimo ustrezne module:
sudo apt-get install postgresql-contrib
Nato v bazi podjetja aktiviramo razširitev pg_trgm, ki omogoča računanje podobnosti med besedami v naravnem jeziku:
sudo su su postgres psql podjetja CREATE EXTENSION pg_trgm;
Sledi izračun indeksov na tabelah podjetij (pogledali si bomo samo primer za Abanko):
CREATE INDEX ikratko_ime_gist on prs_enota_rs USING gist (kratko_ime gist_trgm_ops); CREATE INDEX ipopolno_ime_gist on prs_enota_rs USING gist (popolno_ime gist_trgm_ops); CREATE INDEX ifirma_gist on dutb_podjetja_abanka USING gist (firma gist_trgm_ops);
V nadaljevanju uporabimo ukaz similarity, ki vrne izračun podobnosti med dvema nizoma znakov in sicer na lestvici od 0 (ni podobnosti) do 1 (niza sta identična).
Pri uparjanju s pomočjo podobnosti bomo uporabili nekaj parametrov:
- podobnost med imenom podjetja v DUTB bazi ter PRS registru mora biti vsaj 81% (to mejo smo določili s poskušanjem);
- iščemo samo podobnost med matičnimi podjetji in ne podružnicami (matična številka podjetja se konča z 000).
Podatke je najprej smiselno pregledati in šele potem upariti, to pa zato, da najdemo optimalno mero podobnosti, ki nam bo s kar najmanj napakami uparila čim več vnosov. Primer ukaza za pregledovanje podatkov:
select firma, kratko_ime, prs_enota_rs.davcna, dutb_podjetja_abanka.* from prs_enota_rs, dutb_podjetja_abanka where (similarity(firma::text, kratko_ime::text) > 0.81) and (prs_enota_rs.maticna like '%000');
Ker ima kar nekaj podjetij v DUTB bazi v imenu “v stečaju” ali “v likvidaciji“, to pa pri krajših imenih moti izračun podobnosti, teh besed pri izračunavanju podobnosti ne upoštevamo:
select firma, kratko_ime, prs_enota_rs.davcna, dutb_podjetja_abanka.* from prs_enota_rs, dutb_podjetja_abanka where (similarity(regexp_replace(firma, '^(.* - V (STE.AJU|LIKVIDACIJI)).*$', '\1')::text, kratko_ime::text) > 0.81) and (prs_enota_rs.maticna like '%000') and (dutb_podjetja_abanka.davcna is not NULL);
Mimogrede – pogoj da je davčna številka ničelne vrednosti (davcna IS NULL) smo dodali zato, da se podobnost računa samo na tistih vnosih, ki še niso uparjeni. Uparjanje namreč poteka po korakih.
Podatke uparimo s pomočjo ukaza update. Primer:
update dutb_podjetja_abanka set davcna = prs_enota_rs.davcna from prs_enota_rs where (similarity(regexp_replace(firma, '^(.* - V (STE.AJU|LIKVIDACIJI)).*$', '\1')::text, kratko_ime::text) > 0.81) and (prs_enota_rs.maticna like '%000') and (dutb_podjetja_abanka.davcna is NULL);
V primeru da pride do napak pri uparjanju, je potrebno nekaj ročnega dela. Primer:
update dutb_podjetja_abanka set davcna = 70764492 where (firma = 'T - 2 D.O.O., LJUBLJANA');
Na koncu smo ugotovili, da je pri izračunu podobnosti smiselno postaviti še pogoj, da se pri nizih, ki ju bomo uparjali ujema prvih nekaj znakov, npr. prvih 7 znakov:
update dutb_podjetja_abanka set davcna = prs_enota_rs.davcna from prs_enota_rs where (similarity(regexp_replace(firma, '^(.* - V (STE.AJU|LIKVIDACIJI)).*$', '\1')::text, kratko_ime::text) > 0.50) and (prs_enota_rs.maticna like '%000') and (dutb_podjetja_abanka.davcna is NULL) and (substring(firma from 1 for 7) = substring(kratko_ime from 1 for 7));
Ko smo uparili vse podatke, v DUTB tabelo dodamo še nekaj podatkov nekatere stolpce pa preimenujemo (primer za Abanko, podobno naredimo še za ostale banke):
alter table dutb_podjetja_abanka add column znesek numeric(16,2); alter table dutb_podjetja_abanka add column banka text; alter table dutb_podjetja_abanka add column naziv_clean text; alter table dutb_podjetja_abanka add column posta text; alter table dutb_podjetja_abanka add column postna_stevilka text; alter table dutb_podjetja_abanka add column maticna text; alter table dutb_podjetja_abanka rename column firma to naziv; alter table dutb_podjetja_abanka rename column sedez to naslov; alter table dutb_podjetja_abanka rename column izpostavljenost to znesek_text; update dutb_podjetja_abanka set banka = 'Abanka';
update dutb_podjetja_abanka set naziv_clean = kratko_ime from prs_enota_rs where (prs_enota_rs.davcna = dutb_podjetja_abanka.davcna) and (prs_enota_rs.maticna like '%000');
update dutb_podjetja_abanka set posta = postni_kraj from prs_enota_rs where (prs_enota_rs.davcna = dutb_podjetja_abanka.davcna) and (prs_enota_rs.maticna like '%000');
update dutb_podjetja_abanka set postna_stevilka = prs_enota_rs.postna_stevilka from prs_enota_rs where (prs_enota_rs.davcna = dutb_podjetja_abanka.davcna) and (prs_enota_rs.maticna like '%000');
update dutb_podjetja_abanka set maticna = prs_enota_rs.maticna from prs_enota_rs where (prs_enota_rs.davcna = dutb_podjetja_abanka.davcna) and (prs_enota_rs.maticna like '%000');
update dutb_podjetja_abanka set znesek = replace(replace(replace(znesek_text,' €',''),'.',''),',','.')::decimal(16,2);
Končna struktura tabele je torej naslednja:
- naziv (tip text): naziv podjetja, kot je bil naveden na spletni strani DUTB;
- naslov (tip text): naslov podjetja, kot je bil naveden na spletni strani DUTB;
- znesek_text (tip text): znesek terjatve, kot je bil naveden na spletni strani DUTB;
- davcna (tip integer): davčna številka podjetja;
- znesek (tip numeric(16,2)): znesek terjatve v številski obliki, kar nam omogoča različne izračune;
- banka (tip text): na kateri banki je podjetje imelo slabo terjatev;
- naziv_clean (tip text): naziv podjetja iz PRS registra;
- posta (tip text): naziv pošte kjer ima podjetje sedež iz PRS registra;
- postna_stevilka (tip text): poštna številka podjetja iz PRS registra;
- maticna (tip text): matična številka podjetja.
Podatke iz DUTB tabel za Abanko, Factor banko ter Probanko sedaj vstavimo (dodamo) v skupno tabelo dutb_podjetja:
insert into dutb_podjetja (naziv, naslov, znesek_text, znesek, banka, naziv_clean, posta, postna_stevilka, maticna, davcna) select naziv, naslov, znesek_text, znesek, banka, naziv_clean, posta, postna_stevilka, maticna, davcna from dutb_podjetja_factorbanka; insert into dutb_podjetja (naziv, naslov, znesek_text, znesek, banka, naziv_clean, posta, postna_stevilka, maticna, davcna) select naziv, naslov, znesek_text, znesek, banka, naziv_clean, posta, postna_stevilka, maticna, davcna from dutb_podjetja_probanka; insert into dutb_podjetja (naziv, naslov, znesek_text, znesek, banka, naziv_clean, posta, postna_stevilka, maticna, davcna) select naziv, naslov, znesek_text, znesek, banka, naziv_clean, posta, postna_stevilka, maticna, davcna from dutb_podjetja_abanka;
S tem smo v svojo lokalno bazo podatkov uvozili vse podatke o terjatvah iz DUTB, kar je osnova za izvajanje različnih zanimivih analiz.
Analiza slabih terjatev
Za začetek izračunajmo vsoto vseh slabih terjatev ter preštejmo koliko podjetij je bilo prenesenih na DUTB. Ker se posamezno podjetje lahko nahaja na več bankah, uporabimo ukaz distinct:
sum(znesek) as vsota_terjatev, count(distinct(dutb_podjetja.maticna)) as stevilo_podjetij from dutb_podjetja order by vsota_terjatev desc;
Rezultat:
vsota_terjatev | stevilo_podjetij ----------------+------------------ 4559518937.12 | 536
V nadaljevanju si oglejmo strukturo slabih terjatev po bankah:
select banka, sum(znesek) as vsota_terjatev, count(distinct(dutb_podjetja.maticna)) as stevilo_podjetij from dutb_podjetja group by banka order by vsota_terjatev desc;
Rezultat:
banka | vsota_terjatev | stevilo_podjetij --------------+----------------+------------------ NLB | 2283212938.37 | 283 Abanka | 1140973543.46 | 225 NKBM | 972050458.29 | 233 Probanka | 114242243.00 | 30 Faktor banka | 49039754.00 | 17
In še v grafični obliki:
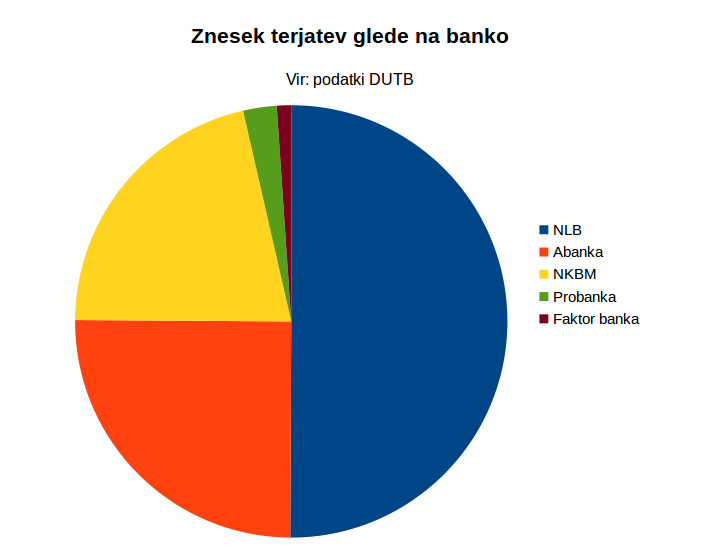
DUTB terjatve glede na banko.
Izračun strukture slabih terjatev glede na regijo sedeža podjetja:
select B.regija, sum(A.znesek) as vsota_terjatev, count(distinct(A.maticna)) as stevilo_podjetij from dutb_podjetja A left outer join prs_enota_rs B on A.maticna = B.maticna group by regija order by vsota_terjatev desc;
Rezultat:
regija | vsota_terjatev | stevilo_podjetij
-----------------------+----------------+------------------
OSREDNJESLOVENSKA | 1798706149.41 | 174
PODRAVSKA | 997431674.93 | 112
SAVINJSKA | 444758935.06 | 75
GORIŠKA | 314338381.56 | 39
GORENJSKA | 292694737.64 | 22
OBALNO-KRAŠKA | 290757367.61 | 27
JUGOVZHODNA SLOVENIJA | 106657031.92 | 16
KOROŠKA | 91625464.80 | 14
| 84708537.70 | 26
POMURSKA | 78284949.74 | 17
NOTRANJSKO-KRAŠKA | 38798457.26 | 7
ZASAVSKA | 15586995.53 | 3
SPODNJEPOSAVSKA | 5170253.96 | 4
Ter še prikaz v grafični obliki:
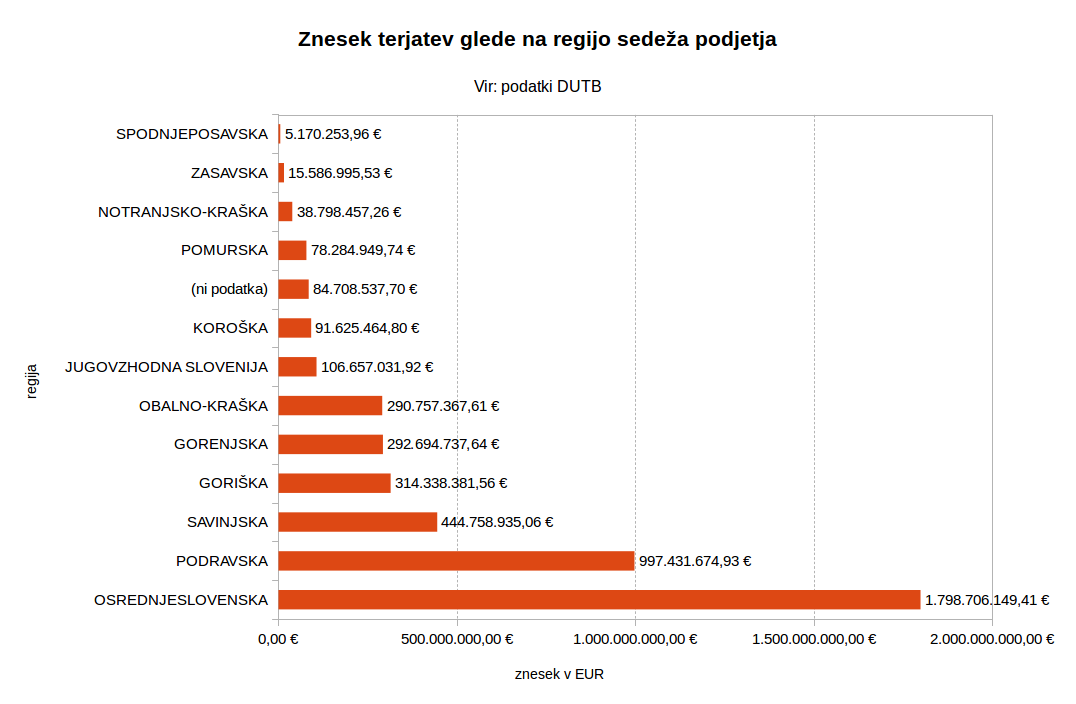
DUTB terjatve glede na regijo sedeža podjetja.
Mimogrede, ker od Ajpesa nismo pridobili zgodovinskega PRS registra, ki vsebuje izbrisane poslovne subjekte, pri 26 podjetjih ne pride do ujemanja, oziroma za ta podjetja nimamo podatkov o sedežu.
Še nekaj zanimivih podatkov:
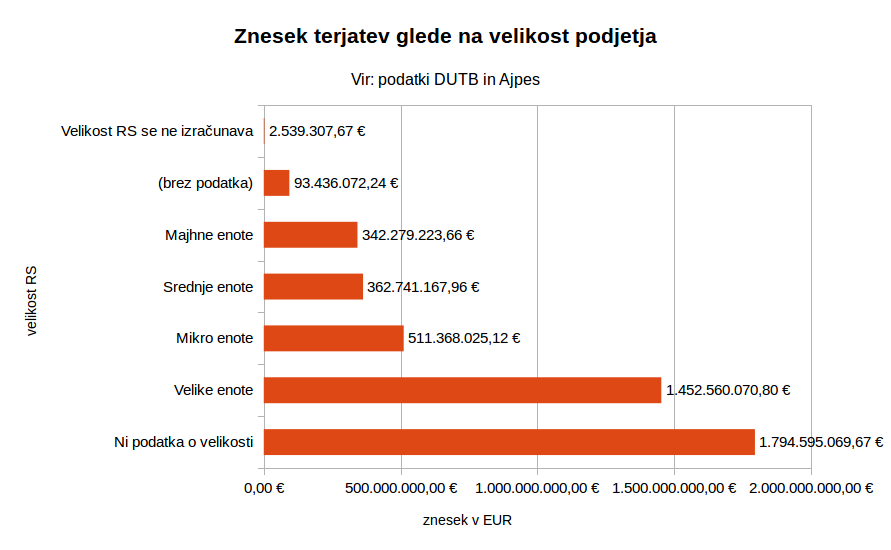
Graf strukture terjatev glede na velikost podjetja (“velikost RS”).
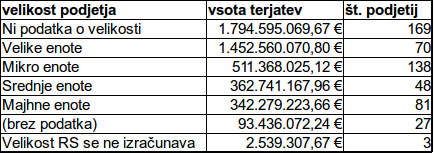
Tabela strukture terjatev glede na velikost podjetja.
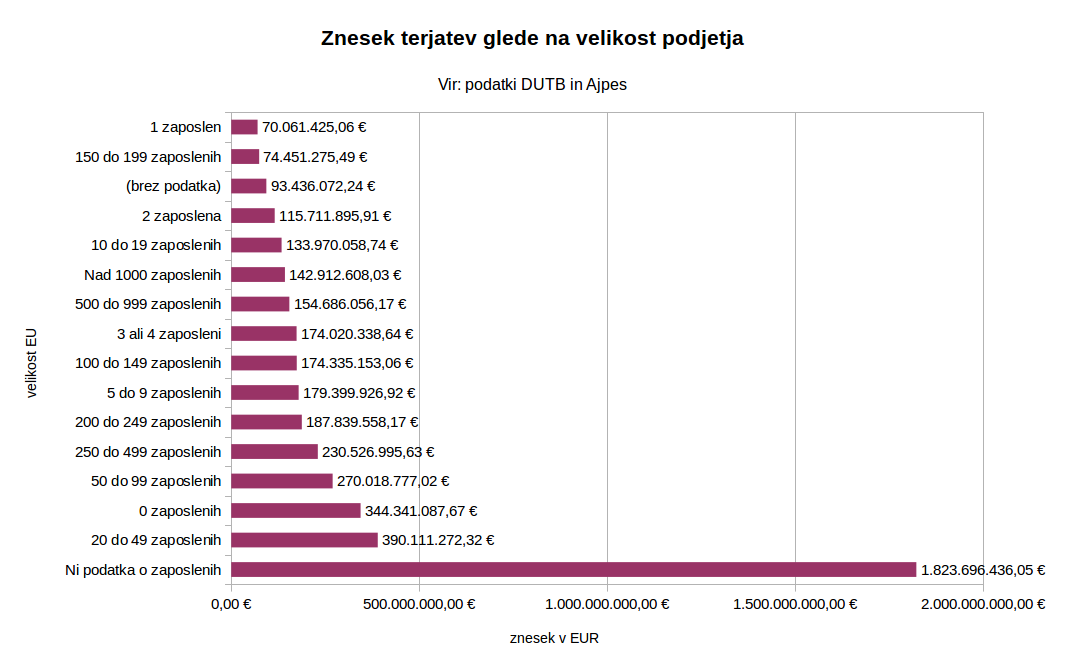
Graf strukture terjatev glede na velikost podjetja (“velikost EU”).

Tabela strukture terjatev glede na velikost podjetja.
Za konec si oglejmo še analizo strukture terjatev glede na registrirano dejavnost podjetja. Najprej uvozimo opise dejavnosti po SKD klasifikaciji: (pozor, CSV datoteka na spletni strani Ajpesa je v CP-1250 naboru znakov)
create table skd (raven text, kategorija text, opis_slo text, opis_ang text, raven_starsa text, prazno text);
\COPY skd from 'SKD_2008_V2.csv' with csv header delimiter ';' encoding 'windows-1250'
alter table skd drop column prazno;
update skd set raven = trim(raven); update skd set kategorija = trim(kategorija); update skd set opis_slo = trim(opis_slo); update skd set opis_ang = trim(opis_ang); update skd set raven_starsa = trim(raven_starsa);
Sledi izračun tabele:
select C.opis_slo as dejavnost, sum(A.znesek) as vsota_terjatev, count(distinct(A.maticna)) as stevilo_podjetij from dutb_podjetja A left outer join prs_enota_rs B on A.maticna = B.maticna left outer join skd C on B.glavna_dejavnost_skd = right(C.kategorija,6) group by C.opis_slo order by sum(A.znesek) desc;
Rezultat (prikazane so samo dejavnosti s terjatvami nad 100 milijonov EUR):
- Dejavnost holdingov: 815.280.869,95 € (30 podjetij)
- Gradnja stanovanjskih in nestanovanjskih stavb: 596.420.273,76 € (49 podjetij)
- Organizacija izvedbe stavbnih projektov: 291.222.882,50 € (20 podjetij)
- Gradnja cest: 250.615.520,95 € (8 podjetij)
- Dejavnost hotelov in podobnih nastanitvenih obratov: 187.626.876,02 € (15 podjetij)
- Trgovina na debelo s kovinskimi proizvodi, inštalacijskim materialom, napravami za ogrevanje: 137.594.220,62 € (6 podjetij)
- Telekomunikacijske dejavnosti po vodih: 133.104.776,40 € (2 podjetji)
- Mehanska obdelava kovin: 107.389.069,47 € (3 podjetja)
- Drugo podjetniško in poslovno svetovanje: 102.815.330,40 € (18 podjetij)
Zaključek
Kot smo torej videli, je z nekaj malega podatkovne analize mogoče pridobiti nekoliko globlji vpogled v strukturo slovenskega javnega dolga. Še zlasti, če podatke o slabih terjatvah povežemo z drugimi bazami podatkov. Mimogrede, v prejšnjem prispevku smo pokazali kako iz podatkov o DUTB podjetjih narišemo graf, ki prikazuje povezave med temi podjetji. S pomočjo brezplačnega programa za analizo omrežij Pajek, smo naredili nekaj analiz povezav med DUTB podjetji, pri čemer je povezava definirana na način, da sta podjetji povezani, če imata ali sta imeli istega zastopnika ali nadzornika.
Z analizo omrežij se v tem prispevku ne bomo podrobneje ukvarjali, a ko podatke nekoliko analiziramo in v njih poiščemo cikle oziroma neprekinjene povezave, se pokažejo zelo zanimivi vzorci.
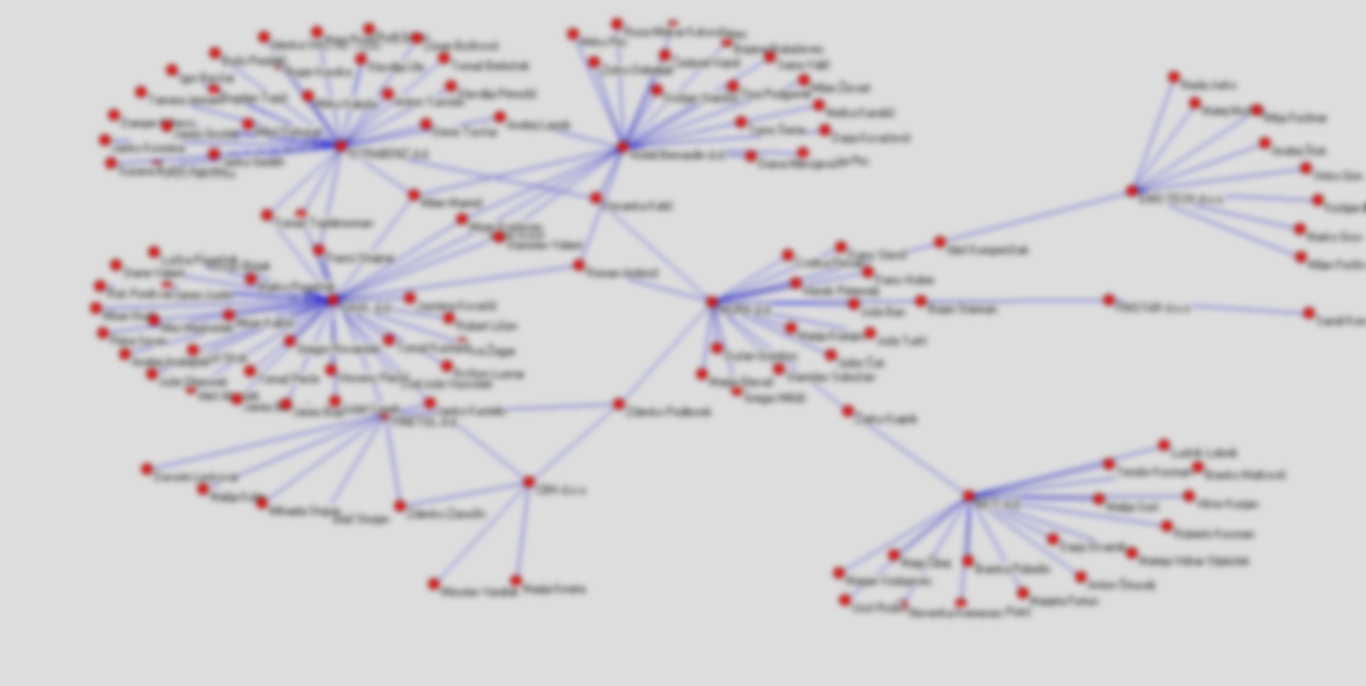
Graf povezav med DUTB podjetji.
Naslednjič si bomo pogledali kako v podatkovno bazo uvoziti podatke o finančnih transakcijah države (tim. Supervizor podatki).
Za vzpodbudo k nadaljnjemu branju pa navajamo le en precej zanimiv podatek.
Vsota vseh slabih terjatev na DUTB znaša 4,5 milijarde EUR (točneje: 4.559.518.937,12 EUR). Ko pa iz Supervizor baze izračunamo skupno vsoto transakcij javnega sektorja (od 1. 1. 2003 do konca septembra 2014) podjetjem, ki so bila prenesena na DUTB, pa ugotovimo, da le ta znaša ravno tako 4,5 milijarde EUR (točneje: 4.580.717.582,1861 EUR).
Slabe terjatve, ki so jih omenjena podjetja “pridelala” v nekaj letih in ki so zdaj postale del javnega dolga so torej “težke” toliko, kot dobrih 10 let poslovanja z državo. Le da je pri v enem primeru država dobila blago in storitve, v drugem primeru pa samo obveznost krpanja bančne luknje.
* * *
Viri podatkov:
- Javne informacije Slovenije – Agencija Republike Slovenije za javnopravne evidence in storitve, datum prevzema PRS registra: 25. september 2014
- Informacije javnega značaja Družbe za upravljanje terjatev bank (DUTB), d.d..
Orodja za podatkovno analizo:
- PostgreSQL 9.3,
- LibreOffice,
- program za analizo omrežij Pajek .
Kopija obdelanih DUTB podatkov v tab-delimited CSV obliki (za uvoz v podatkovno zbirko):
Zahvaljujem se Ajpesu, ki mi je s posredovanjem podatkov iz PRS registra omogočil izdelavo te analize.
Ključne besede: baze podatkov, odprti podatki, Pajek, PostgreSQL